How To Build My Own Website (2) - Markdown
Contents
- The choice of Next.js
- Parse and Display Markdown
- Style my website
- Image Optimization
Parsing and displaying Markdown files are one of the most important things in building a personal website, because all my blogs are written in Markdown. This article illustrates several things that I did in processing Markdown files.
Parse YAML Front Matter
gray-matter is a useful tool to parse YAML front matter. As my old Blog Website is built by Jekyll, which supports parsing YAML by default, all my blog posts used YAML to carry meta information, like this:
---
title: "How To Build My Own Website (2) - Markdown"
date: "2021-03-12T20:00:00+08:00"
categories: Front-End
---with gray-matter parsing:
import matter from 'gray-matter';
const { data, content } = matter(fs.readFileSync(filePath, 'utf8'));the data object is the result of parsing front-matter, and the content is the post content with front-matter stripped.
data: {
title: "How To Build My Own Website (2) - Markdown",
date: "2021-03-12T20:00:00+08:00",
categories: "Front-End",
}, The object returned by gray-matter also has a excerpt property, which can extract excerpt from Markdown files if excerpt is provided in a specified format. However, my old posts didn't have excerpt, and it takes time to fill it again. So I decide to extract several lines of the first paragraph as the excerpt, see below for details.
Convert Markdown To HTML
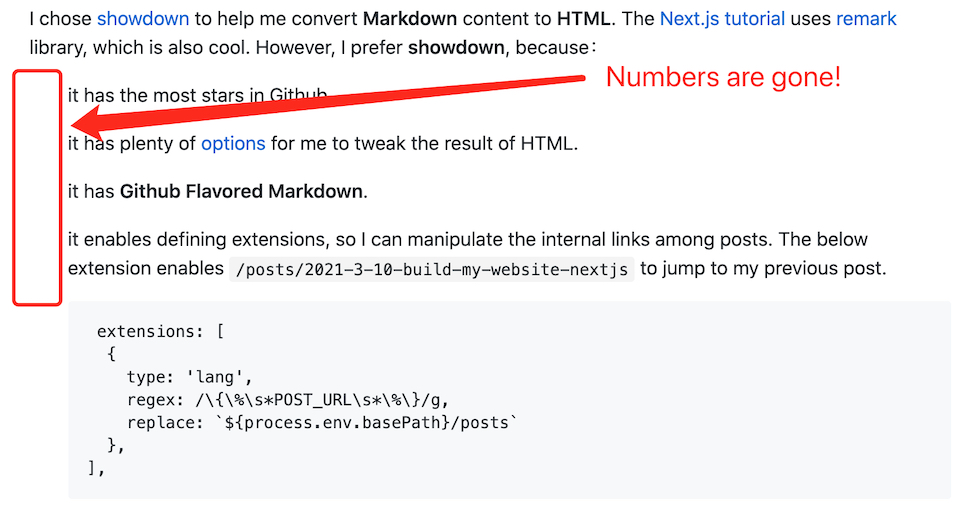
I chose showdown to help me convert Markdown content to HTML. The Next.js tutorial uses remark library, which is also cool. However, I prefer showdown, because:
it has the most stars in Github.
it has plenty of options for me to tweak the result of HTML.
it has Github Flavored Markdown.
showdown.setFlavor('github');it enables defining extensions, so I can manipulate the internal links among posts. The below extension enables
/posts/2021-3-10-build-my-website-nextjsto jump to my previous post.extensions: [ { type: 'lang', regex: /\{\%\s*POST_URL\s*\%\}/g, replace: '/posts' }, ],
Github Flavored Style
I am used to Github Flavored Markdown style. However, I also use tailwindcss as the styling framework in my website. It has default styles which is not suitable for Markdown. So I use github-markdown-css to override the default style, making it Github Flavored. The usage is simple. Import it where the Markdown content renders.
import 'github-markdown-css/github-markdown.css';
export default function MarkdownContent({ content }) {
return (
<div
className="markdown-body"
dangerouslySetInnerHTML={{ __html: content }}
/>
)
}There is a little tweak here. After I apply this .css, I found all the list-style are gone, like this:
After debugging with the browser developer tools, I found that the list-style is given none by tailwindcss, and github-markdown-css doesn't override it.


So I added a Component-Level CSS to override the tailwindcss.
.markdown ol {
list-style: decimal;
}
.markdown ul {
list-style: disc;
}import 'github-markdown-css/github-markdown.css';
import markdownStyles from './markdown-styles.module.css';
export default function MarkdownContent({ content }) {
return (
<div
className={`markdown-body ${markdownStyles.markdown}`}
dangerouslySetInnerHTML={{ __html: content }}
/>
)
}Render LaTeX Math
showdown doesn't have a built-in LaTex parser. Fortunately there is an extension called showdown-katex that renders LaTeX math and AsciiMath using KaTeX. For usage, add it to the extensions's array in the showdown.Converter's construction function:
import showdownKatex from 'showdown-katex';
extensions: [
showdownKatex({
delimiters: [
{ left: "$", right: "$" },
],
}),
],Extract Plain Text
As mentioned above, I need to extract several lines of the first paragraph as the excerpt. However, in spite of the plain text, Markdown contains syntax, which shouldn't be counted. So how to count the plain text in Markdown?
Thanks to mdast, which stands for Markdown Abstract Syntax Tree, the Markdown content can be converted to a syntax tree. Then I can extract only text value by traversing all nodes in the tree. In my case, I only take into account those nodes with a value property. For example,
//text
{type: 'text', value: 'This is text'}
//code
{
type: 'code',
lang: 'javascript',
meta: 'highlight-line="2"',
value: 'foo()\nbar()\nbaz()'
}
//inline code
{type: 'inlineCode', value: 'foo()'}Below are examples of nodes without a value property.
//paragraph
{
type: 'paragraph',
children: [{type: 'text', value: 'This is text'}]
}
//emphasis
{
type: 'emphasis',
children: [{type: 'text', value: 'alpha'}]
},
//list
{
type: 'list',
ordered: true,
start: 1,
spread: false,
children: [{
type: 'listItem',
spread: false,
children: [{
type: 'paragraph',
children: [{type: 'text', value: 'foo'}]
}]
}]
}For details of every node, please check its doc.
To parse Markdown content into mdast, I use remark-parse, a parser for unified.
import unified from 'unified';
import markdownParse from 'remark-parse';
const tree = unified().use(markdownParse).parse(content);Ok, these are the main things that I did with Markdown.
Again, many thanks to those cool guys who contributed to the Markdown work👍☕️