The Interpreter and Runner of uBlockly - Reimplementation of Google Blockly in Unity
Contents
- Introduction
- Blockly Model
- Code Interpreter and Runner
- UGUI Design
For Chinese:
Google Blockly has code generators for translating blocks into code of dynamic languages. Then the code can run on corresponding runtime. It seems quite straightforward and simple. However, we are in Unity. I guess the dominating language in Unity is C#. Correct me if I am wrong😄
C# is static. Obviously it doesn't work like the dynamic languages. So here, we need a interpreter to translate the block behaviors into C# execution functions, and a runner which controls the calling sequence of these functions.
Interpreter
Basically, an interpreter is a function that executes what the block does. However, the execution of a block's behavior may last for a duration, or involve internal state changes. An intuitive way is to use class. But I don't prefer it.
Writing class code may sometimes divide a logic into different pieces in different class methods, e.g. implementing a timer may put the initiation logic in the Start method, the update logic in the Update method, and the reset logic in the Finish method.
This style may make code difficult to read and maintain in the future. I have used React.js for a while. In their improvements, I can see that they are making efforts to encourage us to write less class components, more functional components. The code is more explicit and concise.
So I'd like my interpreter code stay just in a function. I chose IEnumerator. With Unity Coroutine, a function that returns IEnumerator can delay execution, and pause to wait until another process has completed. The code is similar to the async function in Javascript. Below is an example of the interpreter function:
[CodeInterpreter(BlockType = "logic_ternary")]
public class Logic_Ternary_Cmdtor : EnumeratorCmdtor
{
protected override IEnumerator Execute(Block block)
{
CmdEnumerator ctor = CSharp.Interpreter.ValueReturn(block, "IF", new DataStruct(false));
yield return ctor;
DataStruct condition = ctor.Data;
if (condition.BooleanValue)
yield return CSharp.Interpreter.StatementRun(block, "THEN");
else
yield return CSharp.Interpreter.StatementRun(block, "ELSE");
}
}I guess you will argue that it is a class! Honestly, it is a class. But all the code for block behaviors is put in the overrided Execute function. So you only to implement this function for your customized blocks.
The underneath class implementation has some reasons:
Carry data. Blocks may return data for another block to use.
Unify the interface. There are three execution types of the block's behavior:
- a sync function that immediately returns a value.
[CodeInterpreter(BlockType = "logic_boolean")] public class Logic_Boolean_Cmdtor : ValueCmdtor { protected override DataStruct Execute(Block block) { string op = block.GetFieldValue("BOOL"); switch (op) { case "TRUE": return new DataStruct(true); case "FALSE": return new DataStruct(false); } return new DataStruct(false); } }- a sync function that returns nothing,
void.
[CodeInterpreter(BlockType = "controls_flow_statements")] public class Control_FlowStatement_Cmdtor : VoidCmdtor { protected override void Execute(Block block) { LoopCmdtor loopCmdtor = LoopCmdtor.FindParentLoopCmdtor(block); if (loopCmdtor == null) throw new Exception("blocks of \"break\" and \"continue\" can only be put in blocks of loop control types");
}switch (block.GetFieldValue("FLOW")) { case "BREAK": loopCmdtor.SetFlowState(ControlFlowType.Break); return; case "CONTINUE": loopCmdtor.SetFlowState(ControlFlowType.Continue); return; } }- an async function that runs for a duration, or includes the call of the interpreter functions of its child blocks.
[CodeInterpreter(BlockType = "coroutine_wait_frame")] public class Coroutine_WaitFrame_Cmdtor : EnumeratorCmdtor { protected override IEnumerator Execute(Block block) { CmdEnumerator ctor = CSharp.Interpreter.ValueReturn(block, "TIME", new DataStruct(0)); yield return ctor; DataStruct time = ctor.Data;
}for (int i = 0; i < time.NumberValue.Value; i++) { yield return null; } }
So I wrapped all these logic in the underneath abstract class, and only expose the Execute function for the real translating code. If you are interested in the implementation, please click here.
Runner
Given the interpreters of blocks, and a workspace of connected blocks, how to run it? This is what the Runner does.
The basic idea is to traverse the blocks based on the tree based hierarchy, and call the interpreter functions one by one. This calling sequence can't be decided before running, because we have variables which vary overtime and so make the running process unpredictable. In addition, the execution of a parent block may rely on the output of its child blocks.
Unity coroutine manages the running of IEnumerator functions. This was how my initial runner worked:
- Unity coroutine starts running from the topmost block's
IEnumeratorinterpreter function. - In the body of the block's interpreter function, if it meets the
yield returnchild's interpreter function, Unity coroutine will hang up the parent's interpreter function, enter child's, and come back when the child's function has completed. - When a parent block's interpreter function has completed, we check if there is a next block, and continue the process util all blocks complete running their interpreter functions.
Thanks to Unity coroutine, it saved my code to manage the running of nested IEnumerator functions, as mentioned above at the 2nd point. However, in the meantime, I lost the control. Once Unity coroutine started running from the function that I passed in, the process goes into a black box. I couldn't pause the running before or after a certain block.
Unity coroutine has pause API, but it is unknown that whether it is paused at the entry/exit point of a block, or just at the midtime of a YieldInstruction, e.g. yield return new WaitForSeconds().
So I rewrote the coroutine logic based on the iteration feature of IEnumerator. Similiar to JS iterator, it has MoveNext() to move forward the process, and Current to access the current process. This is how it works now:
It maintains a stack of
IEnumerator. In thewhileloop,- each time it peeks the top
IEnumeratorfrom the stack, - runs it by looping
MoveNext(), - if another
IEnumeratoris met, pushes it into the stack, breaks the current loop, returns to step 1. - the
whileloop finishes running when the stack is empty.
This is similar to how the call stack works in a computer program.
- each time it peeks the top
It wraps the interpreter functions into an inherited
IEnumerator, calledCmdEnumerator, so it can identify the entry/exit point of interpreter functions by checking the type of currentIEnumerator.
With this runner, I get the full control of the running process. So I can
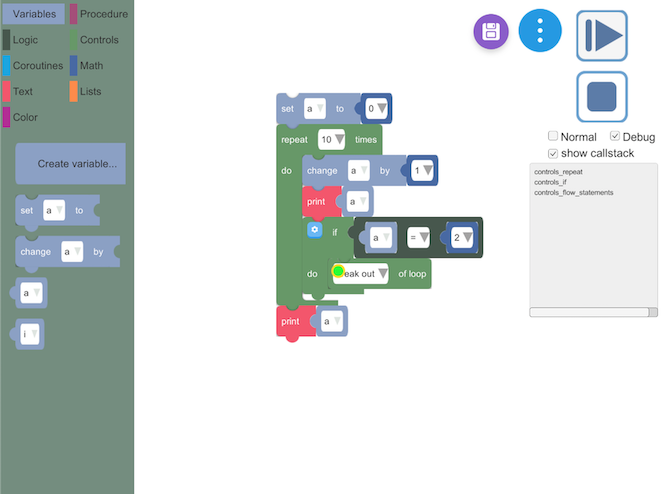
- implement the Debug Mode, that is run the block step by step, like debugging.
- print out the callstack.
- implement stack overflow exception.
Please see this showcase video. If you are interested in the code, please click here.
Data
Variables
Like Google Blockly, we have variables. In the scope of a workspace, we maintain a dictionary of variables, where the key is the name of the variables. So there is a limitation that in the scope of a workspace, the variables can't have duplicate names. Each time the runner starts a fresh run, all the variables in the dictionary are reset to the initial value.
Type Definition
Google Blockly has no concern about the data types, because it's Javascript. But we are here with C#, a strongly typed language. Our interpreter needs to know the exact type of the data passed in. But I don't want to expose the data type to annoy our ublockly users. So I wrapped all the data types that ublockly supports in a struct, called DataStruct.
We support 5 data types:
- Undefined: the data is not assigned with any data, similiar to
undefinedin JS. The default data type. - Boolean:
trueorfalse. - Number: our wrapper struct for numbers, strongly converting datas of boolean, int, float, double, string into float.
- String: the original
stringtype in C#.charwill also be converted into this type. - List:
ArrayListin C#. Allows elements of different types, but unifies the types when conducting math operations, or string joins.
The DataStruct contains the real data and its data type, as well as the overrided operations like +, -, =, etc, providing convenience for data manipulation in ublockly.